기초통계(1)
< 가설,오류,모집단,표본설정,확률분포,유의수준 >
February 24, 2020
- 통계학이란?
- 분위수와 분산
- 가설과 오류
- 모집단과 표본설정
- 확률분포와 검정통계량
통계학이란?
통계학
- 데이터를 통계량(평균 등)이나 그림, 표로 정리하여 그 특징을 파악하는 학문
종류
- 기술통계학 : 데이터의 특징 파악
- 평균, 분산, 상관함수 등
- 대상 : 많은(표본크기가 큰) 데이터
- 추측통계학 : 표본의 정보를 사용하여 모집단의 특성을 추측
- 불편추정, 신뢰구간의 추정(선거 속보, TV시청률), 가설검성, 다변량 분석 등
여러가지 평균
- 산술평균 : 데이터 총합을 데이터의 개수로 나눈 것(평균에서 벗어난 값의 영향을 강하게 받음)
- 기하평균 : 성장률과 이율의 평균값을 계산하고 싶을 때 이용(ex. 연 성장률, 전년대비)
- 조화평균 : 속도나 전기저항의 평균값에 이용(ex. 일정한 거리 이동할 때 평균속도)
데이터의 분산
분위수
- n개의 데이터를 작은 수에서부터 큰 수의 순으로 늘어놓고, 그것을 k등분 했을 때, 그 경계가 된 수치를 분위수라고 함
- 자주 사용되는 것은 사분위수(k=4)
- 수치가 작은 쪽부터 제1사분위수, 제2사분위수(중앙값), 제3사분위수라고 한다.
사분위 범위
- 제3사분위수 - 제1사분위수
- 데이터가 중앙값 주위에 집중할수록 사분위범위는 작아진다.
편차
- 데이터의 값(x) - 평균값(\(\bar{x}\))
- 편차(절댓값)가 큰 데이터가 많으면 분산의 크기가 큰 데이터 세트라고 할 수 있음
분산
- 편차는 개별 데이터에 대해 계산되지만, 분산은 그것을 하나의 지표로 한 것
- 편차 제곱의 평균값
표준편차(std)
- 분산의 양의 제곱근.
- 단위가 데이터와 같으므로 편리
이상치
- 데이터의 평균에서 멀리 떨어져 있는 값
- 이상치인지 확인할 때 가장 많이 쓰는 방법은 그 값이 제 3사분위수와 제 1사분위수로부터 1.5 * \(\text{IQR}\)만큼 오른쪽에 있거나 왼쪽에 있는지를 확인하는 방법
변동계수
- 두 개의 데이터가 흩어진 정도를 비교
- 다른 단위를 가진 그룹 간에 흩어진 정도를 비교할 때 사용
- 변동계수(CV) = 표준편차(S) / 평균(\(\bar{x}\))
상관계수
- 상관의 정도를 나타내는 지표
- ‘한쪽이 증가하면 다른쪽도 증가한다’, ‘한쪽이 증가하면 다른쪽은 감소한다’와 같은 직선적인 관계를 상관이라고 함
- -1에서 1사이의 값을 취함
- 1에 가까우면 양의 상관
- -1에 가까우면 음의 상관
- 0애 가까운 경우는 상관없음
순위상관
- 순위 데이터밖에 사용할 수 없는 경우
- 두 변수 간에 곡선적인 관계가 상정되는 경우
- 스피어만의 순위 상관계수
- 순위 데이터에 대해 계산한 피어슨 확률 상관계수
- 연속변수(연속적인 값을 취하는 변수)일 경우는 먼저 순위 데이터로 변환
- 켄달의 순위 상관계수
- ex) 국어석차 - 영어석차
- x에 대한 순위와 y에 대한 순위가 일치하는지의 여부에 주목해서 상관의 정도를 측정하는 지표
가설과 오류
가설과 가설설정
- 가설 : 어떠한 문제를 검증하기 위해 미리 세우는 결론
- 가설 설정 : 어떤 사실이나 현상에 내재되어 있는 법칙이나 결과를 얻어내기 위해 연구모델을 설계하는 과정에서 수립되는 첫 단계
통계적 가설 검정
- 표본에서 얻은 정보를 통해, 귀무가설과 대립가설 중 어떠한 가설이 옳고 그른지 판단하는 방법
- 귀무가설(\(H_{0}\)) : 보편적으로 옳다고 믿어지는 가설
- 대립가설(\(H_{1}\)) : 기존 주장에 문제점을 제기하는 새로운 가설
오류
- 제 1종의 오류(\(a\)) : 귀무가설이 참인데도 불구하고 귀무가설이 옳지 않다고 판단하는 경우
- 제 2종의 오류(\(b\)) : 귀무가설이 참이 아닌데도 귀무가설을 올바르다고 판단하는 경우
모집단과 표본설정
모집단과 표본
- 모집단 : 특성을 알고자 하는, 연구의 대상이 되는 모든 개체들의 전체 집합
- 모수 : 모집단의 특성을 나타내는 값
- 표본 : 연구를 위해서 모집단에서 추출된 일부
- 표본통계량(=통계량) : 표본의 특성을 나타내는 양(표본을 분석하여 얻어지는 결과치)
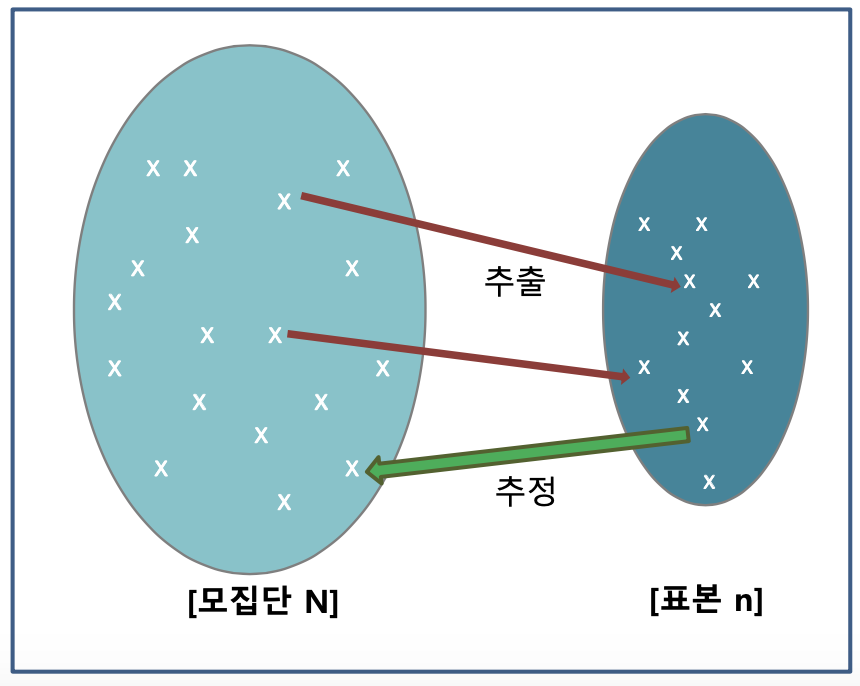
모집단조사와 표본조사
- 모집단조사 : 연구하고자 하는 대상을 모두 조사하는 방식으로 시간과 비용이 많이들고 불가능한 경우가 대다수.
- 표본조사 : 모집단으로부터 추출한 표본을 이용한 조사방식으로 시간과 비용이 절약된다는 장점이 있으나, 표본이 모집단을 대표하지 못한다면 일반화에 제약이 따름.
- 표집오차 : 모집단에서 표본을 추출할 때, 추출된 표본집단이 모집단을 정확하게 반영해주지 못해서 발생하는 오류
표본의 크기 결정
- 표본의 숫자가 커질수록 표집오차가 줄어들고 대표성이 커지지만, 시간과 비용이 많이 들기 때문에 대표성을 확립할 수 있는 최소한의 표본을 구함
- 기본 계산식

표본추출(확률적/비확률적)
- 확률적 표본추출 : 추출확률이 동일한 표본추출로 무작위성, 대표성이 있는 표본으로 일반화 가능,표본 오차 추정 가능
- 단순 무작위 : 모집단 전원에게 1번부터 N번까지 일련번호를 부여한 후에, 이들 중에서 필요한 표본의 크기만큼 임의대로 조사대상을 추출하는 방법
- 계통적 추출 : 추출단위에 일련번호를 부여하고 이를 등간격으로 나눈 후 첫 구간에서하나의 번호를 랜덤 선정한 다음 등간격으로 떨어져 있는 번호들을 각 구간에서 추출하는 방법
- 집락표본 추출법 : 모집단을 소집단으로 나누고 일정수의 소집단을 무작위로 표본추출한 후, 추출된 소집단 내의 구성원들을 모두 조사하는 방식
- 층화표본 추출법 : 모집단을 특정 기준에 따라 상이한 소집단으로 나누고, 이들 각각 소집단들로부터 표본을 무작위로 추출하는 방식
- 비확률적 표본추출 : 추출될 확률이 동등하지 않은 표본추출로 대표성에 제약이 있는 제한된 일반화, 표본오차 추정 불가능
- 편의표본 추출법 : 조사자가 주관적으로 표본을 추출하는 방법(비용이 적게들고 절차가 간단하지만, 대표성과 일반화에 문제가 생김)
- 유의표본 추출법 : 모집단의 의견을 반영할 수 있는 것으로 판단되는 특정집단을 표본으로 선정하는 방법( 모집단에 대한 조사자의 정확한 지식과 판단이 중요하며, 비용이 저렴하지만 대표성과 일반화에 문제가 생김)
- 할당표본 추출법 : 미리 정해진 기준(할당 분량)에 따라 모집단을 여러 집단으로 구분하고 각 집단별로 대상을 추출하는 방법(조사자가 정확한 구성비를 알아야만 사용 가능)
- 스노우볼 : 표본을 구하기 어려운 경우, 소수의 인원을 확보한 후 그 인원을 활용해 주위 사람들을 모으는 방법
확률분포와 검정통계량
확률분포
- 표본공간 : 각 실험에서 얻어질 수 있는 가능한 모든 근원사건의 집합
- 확률 : 표본공간에서 만들어질 수 있는 가능한 모든 사건에 0과 1사이의 값을 대응시키는 함수
- 확률변수 : 표본공간의 각 사건에 실수를 대응시키는 함수, 즉 표본공간을 정의역으로 하고 실수공간을 치역으로 하는 함수
- 확률분포 : 가능한 모든 확률변수와 이 변수가 발생할 확률을 나타낸 것
표본분포
- 표본을 N개 확률변수의 조합이라고 볼 때, 통계량의 확률분포를 의미
- 추출된 표본 통계량의 가능한 모든 확률변수가 이 변수가 발생활 확률
이산분포와 연속분포
- 이산분포 : 정수로 딱 나뉘는 셀 수 있는 경우의 분포(동전을 두 번 던지는 실험에서 앞면이 나오는 수와 같이 셀 수 있음)
- 이항분포 : 연속된 n번의 독립적 시행에서 각 시행이 확률 p를 가질때의 이산확률분포
- 포아송분포 : 단위시간 내에 어떤 사건이 몇 번 발생할 것인지를 표현하는 이산확률분포
- 초기하분포 : n개중에 k개만 찾는 조건이라고 할 때, n개 중 n개를 뽑았을 때 k에 대한 분포
- 베르누이분포 : 실험의 결과가 두 가지 가능한 값만을 가질 때, 일정한 성공확률 p를 갖는 실험
- 연속분포 : 키, 몸무게, 거리 등의 양을 측정할 때와 같이 확률변수가 가지는 값이 구간으로 표시되거나 연속적인 값을 취하는 셀 수 없는 경우의 분포
- 정규분포 : 모든 값을 표현하기에 최대/최소값 없이 무한대로 표현이 가능한 분포
- 표준정규분포(Z분포) : 정규분포 중에서도 평균이 0이고 분산이 1인 특수한 경우의 분포
- 중심극한정리 : 평균 \(\mu\)와 분산 \(\sigma^2\)을 가지는 모집단으로부터 얻은 확률분포의 표본수
- 지수분포 : 사건이 서로 독립적일 때 다음 사건이 일어날 때까지의 대기 시간에 대한 확률분포
표본분포의 종류
- T분포
- 표본의 사례수(n)가 매우 작은 경우에는 표본분포가 정규분포를 이루지 못하기 떄문에 T분포를 사용해야함(표본의 크기가 30이하인 경우)
- 표준정규분포와는 달리 단일분포를 보이지 않고 표본의 크기에 따라 표본분포가 변하는 특징이 있음
- 두 집단간 평균 차이에 대한 가설검정에 주로 사용됨
- F분포
- 두 개의 분산에 관한 추론
- 비교집단이 3개 이상인 경우 사용됨
- 대표적으로 분산분석에 사용되는 분포
- \(\chi^2\)분포
- 실제관찰빈도와 기대빈도의 근접성 검정시 사용
- 주로 명목척도로 측정된 두 변수간 상관관계를 검정에 이용
검정 통계량
- 가설검정을 위해 관찰된 표본으로부터 구해진 통계량
- 분석방법에 따라 사용되는 통계량이 결정되며 일반적으로 표준화된 값들을 사용
유의수준과 신뢰구간
유의수준(\({a}\))과 유의확률(P-value)
- 유의수준(\({a}\)) : 가설 검정 시, 허용 가능한 1종 오류의 최대치로 연구자가 세운 대립가설의 채택 여부를 판단하는 기준
- 유의확률(P-value) : 관측된 표본의 결과가 귀무가설을 지지하는 정도의 확률로 유의수준과 비교해 대립가설의 채택 혹은 기각 여부를 판단함
신뢰구간과 신뢰수준
- 모집단에서 n번의 표본을 추출했을 때, 그 표본이 모평균을 포함하고 있는 구간으로 모집단애서 표본을 추출했을 때, 그 표본이 모집단을 대표할 수 있는지 파악하는 용도로 사용
- 신뢰한계 : 신뢰구간에서 얻어진 구간의 상한과 하한
- 신뢰수준 : 신뢰구간이 실제로 모수(모평균)을 포함하게 되는 정도로 A가 제 1종의 오류를 범하게 될 최대허용치일 때, 신뢰수준은 1-\({a}\)로 표현함