Apache Spark 개념편!
What is Spark?
분석 엔진 툴 - 통합된 분석엔진으로 분석 - ETL같은 데이터를 이동시키고 데이터를 정제
Speed
하둡과 스파크와 비교해보면 100배이상 스파크가 더 빠르다.
- 하둡은 디스크에서 데이터를 처리.
- 스파크는 메모리 위에서 데이터를 처리.
분산병렬처리
- 클러스터 구조로 운영이 된다.
- in-memory (빠른 이유)
Ease of Use
- 여러 언어들 지원(Java, Scala, Python, R, SQL)
- 메인 언어는 Scala
Cluseters
: 여러 컴퓨터들의 자원을 가지고 하나의 컴퓨터 처럼 사용하는 것
- 마스터(Matser)와 슬레이브(Slave)로 구성
클러스터 구조
- Apache Spack
- 컨테이너 기반의 kubernetes
- MySQL
- Hadoop
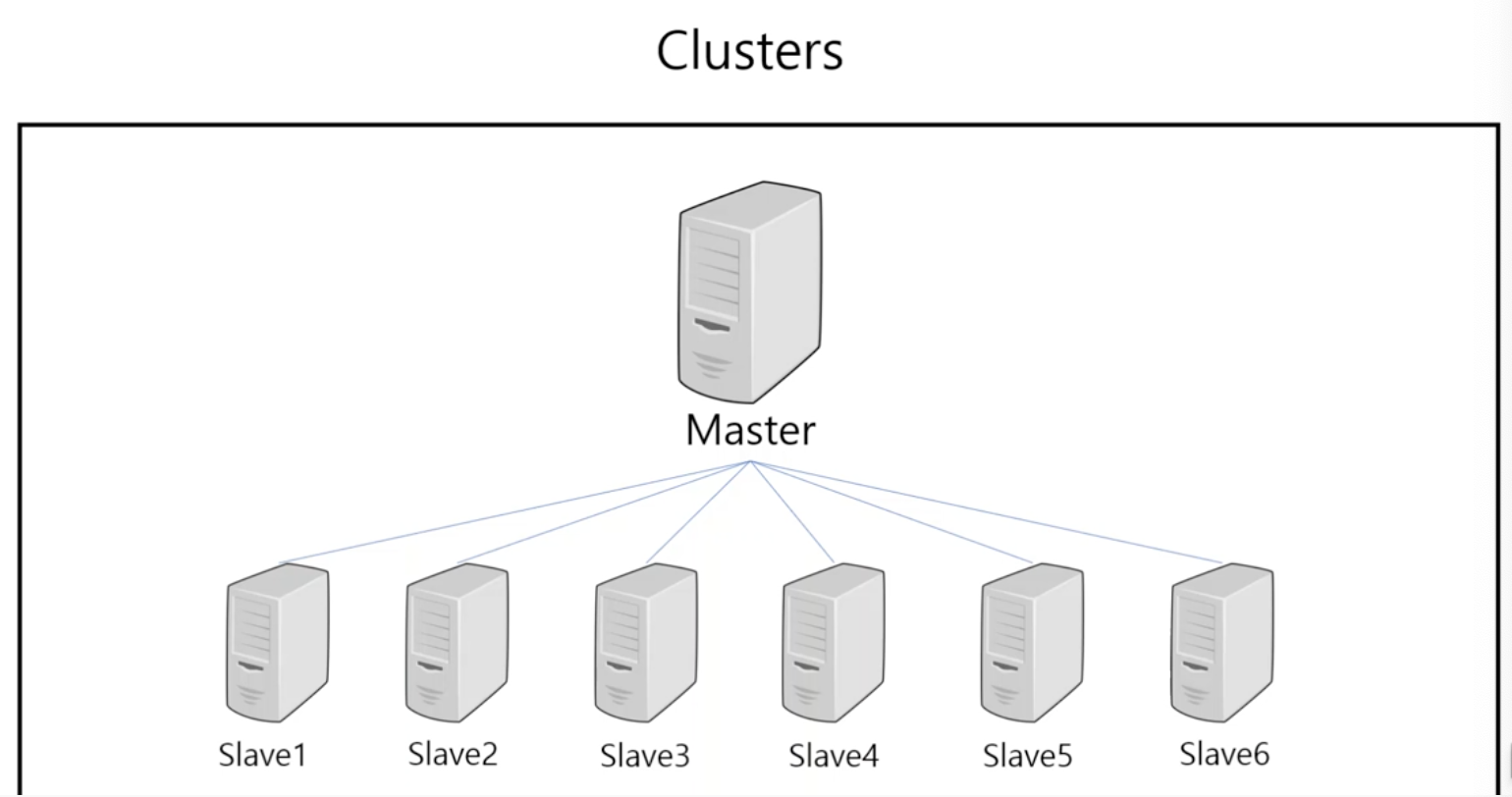
마스터는 여러 컴퓨터들 중 대표, 슬레이브의 자원을 관리해준다.
Apache Spark Process

아파치스파크가 쓰는 데이터프레임, 데이터 셋, RDD 라는 세가지 형태가 있는데 그 중 데이터 프레임을 SQL 언어로 쉽게 정비하거나 데이터를 다룰 수 있다.
머신러닝 같은 경우 머신러닝 관련 라이브러리를 스파크가 가지고 있다.(사용하고 싶은 라이브러리를 코어위에서 설치해서 사용할 수도 있다.)
- 리소스 매니저 (Standalone, YARN, Mesos)
- 클러스터 구조는 안에 많은 자원이있는데 논리적으로 나눠져 있는데 그런 자원들을 어떻게 관리할 것인지 설정하는 것
- 스파크 자체적으로 가지고 있음(따로 설치X) 여러대의 서버를 관리해줄 리소스 매니저 : YARN을 많이 사용
참고
https://www.youtube.com/watch?v=D3TLh_QVGPg